
熱門主題
Microsoft 365
Microsoft 帳戶與儲存空間
Windows 與裝置

認識 Copilot Pro
Copilot 系列中的最新成員可優先存取熱門 AI 模型,而且對於 Microsoft 365 家用版和 Microsoft 365 家用版訂閱者,它是您每天使用的 Microsoft 365 應用程式中的 AI 小幫手。
探索
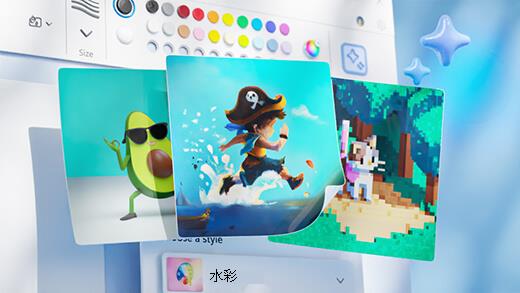
使用 Paint Cocreator 生成藝術
只要使用幾個字,就能創造出令人讚歎的藝術作品。 Microsoft Paint Cocreator 可在 AI 的協助下,協助您發揮創意並製作出自己的藝術作品。

在 Windows 中使用 AI 達成更多目標
Windows 是第一個提供集中式 AI 協助的電腦平臺。 瞭解如何在 Windows 中使用 Copilot 達成並建立更多目標。



使用 Microsoft 365 快速完成更多工作
快速建立和共用傑出的內容、輕鬆管理您的排程、輕鬆與其他人交流,以及感到安心無虞,這一切全都透過 Microsoft 365 完成。