
Chào mừng bạn đến với Bộ phận hỗ trợ của Microsoft
Vui lòng đăng nhập để chúng tôi phục vụ bạn tốt hơn Đăng nhập
Xin chào, , chào mừng bạn đến với Bộ phận hỗ trợ của Microsoft
Các chủ đề thịnh hành
Tài khoản Microsoft & lưu trữ

Làm quen với Microsoft Copilot
Đạt được bất cứ điều gì bạn có thể tưởng tượng với người bạn đồng hành AI của mình trong các ứng dụng bạn đã sử dụng hàng ngày.
Khám phá
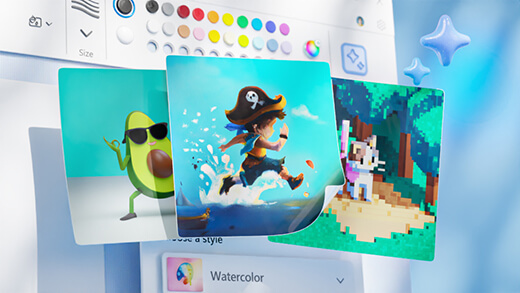
Tạo nghệ thuật với Paint Cocreator
Tạo ra tác phẩm nghệ thuật tuyệt vời chỉ với một vài từ. Microsoft Paint Cocreator sẽ giúp bạn thỏa sức sáng tạo và tạo ra những tác phẩm nghệ thuật của riêng mình với sự trợ giúp của AI.

Đạt được nhiều hơn với AI trong Windows
Windows là nền tảng PC đầu tiên cung cấp hỗ trợ AI tập trung. Tìm hiểu cách đạt được và tạo nhiều hơn với Copilot trong Windows.

Office hiện là Microsoft 365
Trang chủ cho các công cụ và nội dung yêu thích của bạn. Giờ đây với những cách mới giúp bạn tìm, tạo và chia sẻ nội dung của mình, tất cả ở cùng một nơi.

Trung tâm đào tạo về Microsoft 365
Làm việc hiệu quả nhanh chóng với những Microsoft 365 video, hướng dẫn và tài nguyên này.
Câu chuyện thành công về doanh nghiệp nhỏ của Microsoft 365

Nếu bạn là chủ sở hữu doanh nghiệp nhỏ
Tìm thông tin bạn cần để xây dựng, vận hành và phát triển doanh nghiệp nhỏ của bạn với Microsoft 365.
Tùy chọn hỗ trợ khác
Hãy liên hệ với Bộ phận hỗ trợ
Hỗ trợ dành cho doanh nghiệp lớn
Quyền riêng tư và bảo mật
Xem thêm hỗ trợ

Làm được nhiều hơn với Copilot Pro
Tăng cường khả năng sáng tạo và năng suất của bạn với trải nghiệm Copilot premium. Tải xuống ứng dụng Copilot để dùng thử Copilot Pro 1 tháng miễn phí.