
Bem-vindo ao Suporte da Microsoft
Entre para que possamos atender melhor Entrar
Olá, , bem-vindo ao Suporte da Microsoft.
Tópicos mais populares
conta e armazenamento da Microsoft
Windows e dispositivos

Conheça o Microsoft Copilot
Alcance tudo o que você pode imaginar com seu companheiro de IA nos aplicativos que você já usa todos os dias.
Explorar
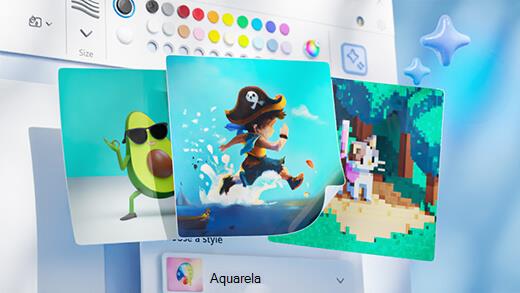
Gerar arte com o Cocriador do Paint
Crie uma arte incrível com apenas algumas palavras. O Cocriador do Microsoft Paint ajudará você a liberar sua criatividade e fazer suas próprias obras de arte com a ajuda da IA.

Obter mais com a IA no Windows
O Windows é a primeira plataforma de computador a fornecer assistência centralizada de IA. Saiba como obter e criar mais com o Copilot no Windows.

O Office agora é Microsoft 365
A página inicial das suas ferramentas e conteúdo favoritos. Agora, com novas maneiras de ajudá-lo a encontrar, criar e compartilhar seu conteúdo, tudo em um só lugar.

Centro de Treinamento do Microsoft 365
Seja produtivo rapidamente com esses vídeos, tutoriais e recursos do Microsoft 365
Histórias de sucesso de pequenas empresas do Microsoft 365

Se você é um proprietário de uma pequena empresa
Encontre as informações necessárias para criar, executar e expandir sua pequena empresa com o Microsoft 365.
Mais opções de suporte
Fale com o suporte
Suporte corporativo
Segurança e privacidade
Mais suporte

Obtenha mais com o Copilot Pro
Aumente sua criatividade e produtividade com uma experiência do Copilot premium. Baixe o aplicativo Copilot para uma avaliação gratuita de 1 mês do Copilot Pro.