
Dobro došli u aplikaciju Microsoft Support
Prijavite se, da bismo vam mogli bolje pomoći Prijava
Pozdrav, , dobro došli u aplikaciju Microsoft Support
Popularne teme
Microsoft 365
Microsoftov račun i pohrana
aktivacija
Uređaji sa sustavom Windows

Upoznajte Microsoft Copilot
Postignite sve što možete zamisliti uz AI pomoćnika u aplikacijama koje već koristite svaki dan.
Istraživanje
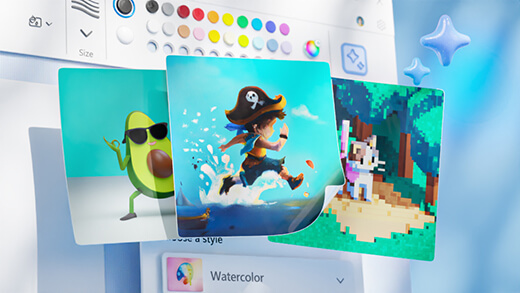
Generirajte crtež uz Paint Cocreator
Stvorite fantastična umjetnička djela uz samo nekoliko riječi. Microsoft Paint Cocreator pomoći će vam da oslobodite svoju kreativnost i izradite vlastita umjetnička djela uz pomoć umjetne inteligencije.

Postignite više uz AI u sustavu Windows
Windows je prva platforma PC-ja koja pruža centraliziranu AI pomoć. Saznajte kako postići i stvoriti više uz Copilot u sustavu Windows.

Office je sada Microsoft 365
Mjesto za vaše omiljene alate i sadržaje. Sada s novim mogućnostima traženja, stvaranja i zajedničkog korištenja sadržaja na jednom mjestu.

Centar za obuku za Microsoft 365
Brzo povećajte produktivnost uz Microsoft 365 videozapise, vodiče i resurse.
Priče o uspjehu malih tvrtki koje koriste Microsoft 365

Ako ste vlasnik male tvrtke
Pronađite informacije koje su vam potrebne za stvaranje, pokretanje i razvoj male tvrtke uz Microsoft 365.
Dodatne mogućnosti podrške
Obratite se podršci
Podrška za velike tvrtke
Zaštita privatnosti i sigurnost
Dodatna podrška

Dobijte više uz Copilot Pro
Unaprijedite svoju kreativnost i produktivnost uz premium sučelje za Copilot. Preuzmite aplikaciju Copilot za 1-mjesečnu besplatnu probnu verziju ponude Copilot Pro.