
Le damos la bienvenida al Soporte técnico de Microsoft
Inicie sesión para que podamos ayudarle mejor Iniciar sesión
Hola: , le damos la bienvenida al Soporte técnico de Microsoft
Temas más populares
Cuenta Microsoft y almacenamiento

Conozca Microsoft Copilot
Consiga todo lo que pueda imaginar con su complemento de IA en las aplicaciones que ya usa a diario.
Explorar
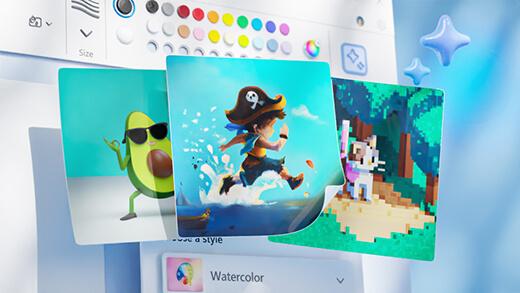
Genere arte con Paint Cocreator
Cree increíbles obras de arte con tan solo unas pocas palabras. Microsoft Paint Cocreator le ayudará a dar rienda suelta a su creatividad y a crear sus propias ilustraciones con la ayuda de IA.

Consiga más con IA en Windows
Windows es la primera plataforma de PC que proporciona asistencia de IA centralizada. Obtenga información sobre cómo lograr hacer más y crear más con Copilot en Windows.

Office ahora es Microsoft 365
La página principal de sus herramientas y contenido favoritos. Ahora, con nuevas formas de ayudarle a encontrar, crear y compartir su contenido, todo en un solo lugar.

Centro de aprendizaje de Microsoft 365
Empiece a ser productivo rápidamente con estos Microsoft 365 vídeos, tutoriales y recursos.
Historias de éxito de pequeñas empresas con Microsoft 365

Si es propietario de una pequeña empresa
Encuentre la información que necesita para crear, ejecutar y hacer crecer su pequeña empresa con Microsoft 365.
Más opciones de soporte técnico
Póngase en contacto con el servicio de soporte técnico.
Soporte técnico a empresas
Privacidad y seguridad
Más soporte técnico

Obtenga más con Copilot Pro
Potencie su creatividad y productividad con una experiencia de Copilot de primera calidad. Descargue la aplicación Copilot para obtener una prueba gratuita de Copilot Pro durante 1 mes.